AutoSpotting - Frequently Asked Questions
Looking for more info about AutoSpotting? Here are some things we're commonly asked.
What is AutoSpotting?
AutoSpotting is a tool that makes it easy to adopt EC2 Spot instances in AutoScaling groups, for up to 90% savings. It is enabled and configured using tags and requires no launch template or launch configuration changes.
What are Spot instances and how do they work?
Cloud providers such as Amazon AWS need to always have some spare capacity available, so that any customer willing to launch new instances would be able to do it without getting errors.
AWS offers this spare capacity to customers as EC2 Spot instances, at a steep discount, but they will take it back within minutes when it needs to be allocated to on-demand users.
From the functionality perspective Spot instances are identical to on-demand instances, the only difference is the fact that they can be interrupted when AWS needs that capacity for someone else.
How reliable are Spot instances?
Individual instances will be interrupted occasionally, but stateless workloads can usually sustain individual instance interruptions.
If your application may run on multiple instance types, when capacity for one of them is running low you can get capacity from other instance types.
AutoSpotting automatically diversifies over multiple instance types on your behalf, and also in the unlikely event of insufficient capacity for all of them it would failover to OnDemand instance types over the same range of instance types.
Which workloads are tolerant to Spot interruptions?
Spot is a great fit for fault tolerant, stateless workloads that have some instance type flexibility.
Most workloads running on AutoScaling groups that scale dynamically or sit behind
HTTP load balancers or consume data from SQS queues are also good candicates to Spot,
because new requests can be routed quickly to new instances without any visible
user impact. Containerized applications and big data processing are also a great fit for Spot instances.
How does AutoSpotting work?
AutoSpotting monitors the AutoScaling groups where it was enabled and continuously replaces their on-demand instances with compatible and identically configured Spot instances.
It will by default replace all on-demand instances with Spot but it can also keep some of them running as on-demand if configured so.
How are Spot interruptions handled by AutoSpotting?
The interruptions are published by AWS in the instance metadata and as EventBridge events.
AutoSpotting listens for EventBridge events and proactively detaches the Spot instances from load balancers and ECS, terminates them gracefully, and provisions new Spot instances to replace them.
What are the goals and design principles of AutoSpotting?
AutoSpotting is designed to enhance AutoScaling groups for lower costs, increased reliability, performance and reduced carbon footprint.
We try to be as close as possible to invisible, usually it just does it thing without you noticing anything.
It's also designed towards mass rollouts, such as across entire AWS organizations, where it can sometimes be executed in opt-out mode, converting the entire infrastructure to Spot instances.
The configuration is designed to be minimalist and everything should just work without much tweaking. You're not expected to need to determine which instance types are as good as your initial ones, which instance type is the cheapest in a given availability zone, and so on.
Everything should be determined automatically based on the existing configuration. Your main job is to make sure your application can sustain instance failures.
It also tries as much as possible to avoid locking you in, so if you later decide that Spot instances aren't for you and you want to revert to your initial on-demand setup, you can easily do it with just a few clicks or commands, unlike most other solutions where the back-and-forth migration effort may become quite significant.
From the security perspective, it was carefully configured to use the minimum set of IAM permissions needed to get its job done. Unlike many alternatives in this space, there is no cross-accounting IAM role, everything runs from within your AWS account and no information about your infrastructure ever leaves your AWS account.
What is the use case in which AutoSpotting makes most sense to use?
Any workload which can be quickly drained from soon to be terminated instances and starts quickly on new instances.
AutoSpotting is designed to work best with relatively similar-sized, redundant and somewhat long-running stateless instances in AutoScaling groups, running workloads easy to transfer or re-do on other nodes in the event of Spot instance terminations. Here are some classical examples:
◦ Development environments where maybe short downtime caused by Spot terminations is not an issue even when instances are not drained at all.
◦ Stateless web server or application server tiers(including in Production) with relatively fast response times (less than a minute in average) where draining is easy to ensure.
◦ Batch processing workers taking their jobs from SQS queues, in which the order of processing the items is not so important and short delays are acceptable.
◦ Docker container hosts in ECS, Kubernetes or Swarm clusters when backed by Autoscaling groups.
What are some use cases in which it's not a good fit and what to use instead?
Anything that doesn't really match the above cases:
◦ Groups that have no redundancy, and where terminations impact users.
If you have a single instance in the group, Spot terminations may often leave your group without any nodes for a few minutes. If this is a problem, you should not run AutoSpotting in such groups, but instead use reserved instances, maybe of T2 burstable instance types if your application works well on those.
◦ Instances which can't be drained quickly
If your application is expected to serve long-running requests, without the ability to save the state of the processing, AutoSpotting(or any Spot automation) may not be for you, and you should be running reserved instances.
◦ Cases in which the order of processing queued items is strict
Spot instance termination may impact such use cases, you should be running them on on-demand or reserved instances.
◦ Stateful workloads
AutoSpotting doesn't support stateful workloads out of the box, particularly in case certain EBS persistent volumes need to be attached to running instances.
The replacement Spot instances will be started but additional configuration would have to be in place in order to attempt the attach operation a number of times.
How do I install AutoSpotting?
You can launch it from the AWS Marketplace using the provided CloudFormation template mentioned at the end of the Marketplace installation wizard, it just takes a couple of minutes.
The same CloudFormation template can also be used for launching a StackSet against your entire AWS organization to enable it at large scale.
For Terraform you can use the example below after signing up on the Marketplace, but make sure to use the latest available version from the Terraform Registry
module "autospotting" {
source = "AutoSpotting/autospotting/aws"
version = "1.2.2-0"
name = "AutoSpotting"
environment = "dev"
autospotting_regions_enabled = ["us-east-1", "eu-west-1"]
lambda_cpu_architecture = "x86_64"
notify_email_addresses = [ "user@example.com"]
}
The below video explains in detail the installation process and the available configuration options:
How do I enable AutoSpotting?
The entire configuration is based on tags applied on your AutoScaling groups, usually without any other configuration changes..
By default AutoSpotting runs in "opt-in" mode, so it will only take action against groups after they are tagged as per its expectations.
In the default configuration it expects the "spot-enabled" tag set to "true", and processes groups across all the enabled regions.
All you need to do is apply this tag on your groups with your favorite tagging mechanism, such as infrastructure code tools like CloudoFormation or Terraform, the AWS CLI, or even mass-tagging tools like awstaghelper.
We now also have an easy to use Open Source GUI tool that can estimate the Spot savings and then create the configuration tags with just a couple of clicks, you can check it out here.
Below you can see an example on how it should look like in the AWS console once we're done.
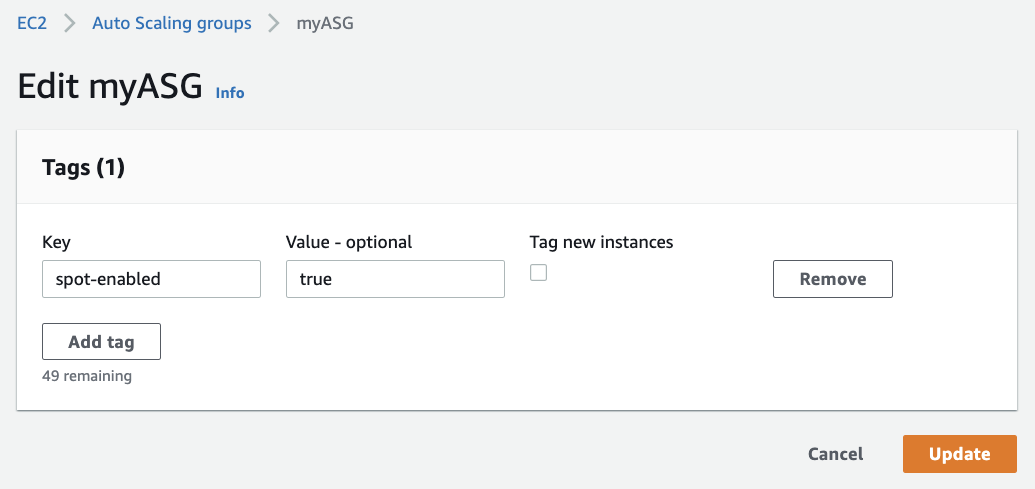
For more advanced users it can also be configured to run in "opt-out" mode, so it will run against all groups except for those tagged with the "spot-enabled" tag set to "false". This mode is unique to AutoSpotting, and when combined to a StackSet deployment it is a great way to adopt Spot at any scale, and without need of further configuration options.
Some large companies have been using AutoSpotting in "opt-out" configuration even across AWS organizations with hundreds of AWS accounts to ensure the majority of their infrastructure to run on cost-effective Spot instances and migrated to Spot in very short time, in some cases literally overnight, without requiring engineering effort from their development teams.
If you are also considering such a rollout and would like support from someone who did it repeatedly and knows how to get the most of AutoSpotting in such a large-scale migration project, we're happy to help and also offering significant discounts over the Marketplace offering, just reach out to us using the chat feature from this page.
Note: the keys and values of the "opt-in"/"opt-out" tags are configurable in both modes, and multiple tags can be used.
The below demo shows how to enable AutoSpotting on a new AutoScaling group.
Will it replace all my on-demand instances with Spot instances?
Yes, that's the default behavior (we find it quite safe), but for your peace of mind this is configurable, as you can see below.
Can I keep some on-demand instances running just in case?
Yes, you can set an absolute number or a percentage of the total capacity, using the global configuraton set at install time, or you can override it on a per-AutoScaling group basis using tags set on each group.
These tags are mentioned when installing the CloudFormation template and can also be set conveniently with just a couple of clicks using our GUI tool.
How does AutoSpotting compare to the AutoScaling mixed groups?
AutoSpotting has a few additional capabilities:
◦ configuration using tags, without having to configure diversified instance types for each AutoScaling group when adopting Spot instances. All you need to do is tag the groups.
◦ automated fail-over to on-demand instances when Spot capacity is unavailable and back to Spot soon once Spot capacity becomes available again.
◦ automated selection of the diversified instance types from the cheapest available instance types, but also with preference toward newest instance type generations for more performance and smaller carbon footprint.
◦ you can enable/disable it at will from CI/CD pipelines and even on a schedule basis by setting the expected tags to different values.
◦ you can roll it out across your entire fleet in opt-out mode, without any configuration changes, in particular you don't need to convert your groups to LaunchTemplates, for example if you still run LaunchConfigurations and want to benefit from Spot instances and diversification.
◦ flexible/automated instance type selection for Spot instances.
Current limitations:
◦ no support for the AWS regions located in China or GovCloud, mainly because we don't have access to them, but it may be ported if needed.
How does AutoSpotting compare to commercial alternatives such as Spot.io?
Many of these commercial alternatives have in common a number of things:
◦ SaaS model, requiring admin-like privileges and cross-account access to all target AWS accounts which usually raises eyebrows from security auditors. They can read a lot of information from your AWS account and send it back to the vendor so they make use of this data about your setup.
Instead, AutoSpotting is launched within each target account so it needs no cross-account permissions, and no data is taken out of your account.
◦ They sometimes implement new constructs that mimic existing AWS services and expose them with proprietary APIs, such as clones of AutoScaling groups, maybe sometimes extended to load balancers, databases and functions, which expect custom configuration replicating the initial resources from the AWS offering. This makes it quite hard and work-intensive to migrate towards but also away from them, which is a massive vendor lock-in mechanism. Many of these resources require custom integrations with AWS services, which need to be implemented by the vendor.
Instead, AutoSpotting's goal is to be integrated as tightly as possible with AWS, and easy to install and remove, so there's no vendor lock-in. Under the hood it's still a plain AutoScaling group, and all its integrations like lifecycle hooks are available out of the box.
◦ they're all pay-as-you-go solutions charging a large percentage of the savings, in the 20-25% range, mainly for the value add of having a GUI dashboard.
AutoSpotting's goal is to simply be as useful and as invisible as possible, also from the price perspective, where we do our best to maximize your savings.
We do have an estimator and periodic savings reports, but no dashboard at the moment.
If you need to see a saving dashboard, you can look at the Cost Explorer section of the AWS console and see how your costs reduce over time.
How much does it cost me to run it?
AutoSpotting is designed to have minimal footprint, and its execution overhead will only cost you a few pennies monthly.
It is based on AWS Lambda, the default configuration is triggering the Lambda function once every 30 minutes, and most of the time it runs for just a few seconds, just enough to evaluate the current state and notice that no action needs to be taken.
In case instance replacement actions are taken it may run for more time because the synchronous execution of some API calls takes more time, but most of the times it finishes in a couple of minutes. It should still be well within the monthly Lambda free tier, you will only pay a few cents for logging and network traffic performed against AWS API endpoints.
The Cloudwatch logs are by default configured with a 7 days retention period which should be enough for debugging, but shouldn't cost you much. If desired, you can easily configure the log retention and execution frequency to any other values in the CloudFormation stack parameters.
How about the software costs?
We've always offered a completely free and open source version of AutoSpotting, which is still available onGitHuband open for external contributions, but not actively developed by the main author anymore.
The latest version under active development is only available from the AWS Marketplace, as prebuilt binaries that have been thoroughly tested. It includes a number of additional features and improvements not available in the Open Source version.
The commercial version charges up to 5% the generated savings through the AWS Marketplace, and is automatically included in your AWS bill.
Does AutoSpotting continuously search and use cheaper Spot instances?
Or in other words if I attach autoSpotting to an AutoScaling group that is 100% Spot instances, will it replace them with cheaper compatible ones when found later on?
The answer is No. The current logic won't terminate any running Spot instances as long as they are running.
The only times when AutoSpotting interacts with your instances is when they are launched or terminated, such as after scaling actions or Spot instance terminations.
I enabled AutoSpotting but nothing happens. What may cause this?
The most common reason is having typos in the tags expected by AutoSpotting or tagged on the groups. Make sure these match. The Lambda function logs should show if the groups are considered for processing.
Assuming the installation of AutoSpotting completed successfully, and you correctly set up AutoSpotting on an existing group, it may take up to 30min to see the first instance replacements. You may try increasing the group capacity to see if a newly launched instance gets replaced.
Spot instances may also fail to launch for a number of reasons, such as Spot market conditions that manifest in low capacity across all the compatible instance types, in which case you'll get failover on-demand instances launched to maintain constant capacity.
Which IAM permissions does AutoSpotting need and why are they needed?
You can see the current IAM permissions in the CloudFormation template and Terraform code.
It basically boils down to the following:
◦ describing the resources you have in order to decide what needs to be done
(things such as regions, instances, Spot prices, existing Spot requests,
AutoScaling groups, etc.)
◦ launching Spot instances
◦ attaching and detaching instances to/from Autoscaling groups
◦ terminating detached instances
◦ logging all actions to CloudWatch Logs
◦ billing to the AWS Marketplace
◦ loading/saving configuration values to SSM
In addition to these, the AutoSpotting Lambda function's IAM role also needs another special IAM permission called "iam:passRole", which is needed in order to be able to clone the IAM roles used by the on demand instances when launching the replacement Spot instances. This requirement is also pretty well documented by AWS.
How do I Uninstall it?
You just need to delete the CloudFormation or Terraform stack.
The groups will eventually revert to the original state once the Spot market price fluctuations terminate all the Spot instances. In some cases this may take months, but you can also terminate them immediately if you want to speed it up.
Fine-grained control on a per group level can be achieved by removing or setting the "spot-enabled" tag to any other value. AutoSpotting only touches groups where this tag is set to "true".
Note: this is the default tag configuration, but it is configurable so you may be using different values.